Отсев неэффективных работников на этапе подбора
Если вы сочтете, что данный материал не имеет отношения в теме e learning, напишите в комменты, но я считаю, что система Webtutor - хорошая место для сбора подобной информации и последующего анализа.
Кроме того, Websoft и Лаборатория "Гуманитарные Технологии" договорились об интеграции своих продуктов, и теперь у клиентов Вебсофта есть возможность проводить тестирование через Вебтютор
Итак
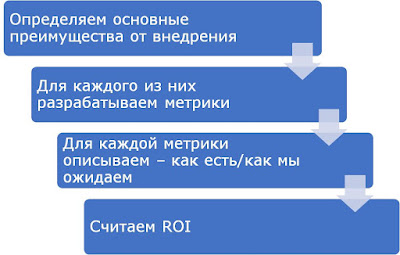
При приеме на работу кандидаты в продажники проходили тестирование по тесту CPI, в дальнейшем замеряли их эффективность. Оценка эффективности состояла из оценки экспертов и состояла из трехбальной шкалы:
Принимаю все замечания, но часто у нас нет количественных мер оценки деятельности, поэтому мы можем воспользоваться оценкой экспертов (разработчики моделей компетенций: разве не тот же метод вы используете?)
Я опущу некоторые шаги (подробнее Прогноз эффективности на основе теста CPI), сразу скажу, что значимо делит неэффективных и остальных шкалы Sp и Do.

Зеленая линия показывает распределение показателей шкалы Do неэффективных, красным - остальных. Серая область - неопределенность прогноза.
Т.е. если кандидат покажет при приеме на работу результат 45 баллов по шкале Sp, это не гарантирует нам, что он обязательно будет неэффективным. Сохраняется вероятность, что он может быть нормальным работником. Те, кто показывают результаты между 50 и 55 баллами, находятся в еще бОльшей зоне неопределенности.

В данном случае мы неэффективными назвали 17 работников по результатам теста, но из них только 50 % реально неэффективные.

Кроме того, Websoft и Лаборатория "Гуманитарные Технологии" договорились об интеграции своих продуктов, и теперь у клиентов Вебсофта есть возможность проводить тестирование через Вебтютор
Итак
Кейс про то, как отбирать неэффективных работников на этапе подбора
При приеме на работу кандидаты в продажники проходили тестирование по тесту CPI, в дальнейшем замеряли их эффективность. Оценка эффективности состояла из оценки экспертов и состояла из трехбальной шкалы:
- высокоэффективные,
- средне эффективные,
- низкоэффективные
Принимаю все замечания, но часто у нас нет количественных мер оценки деятельности, поэтому мы можем воспользоваться оценкой экспертов (разработчики моделей компетенций: разве не тот же метод вы используете?)
Итак
наша задача - отсеять неэффективных. Для этого мы делим группу на 1 - неэффективные ("3" группа) и 0 - остальные ("1" и "2" группа)Я опущу некоторые шаги (подробнее Прогноз эффективности на основе теста CPI), сразу скажу, что значимо делит неэффективных и остальных шкалы Sp и Do.
- Социальное присутствие (Sp)
- Доминирование (Do)
Диаграмма распределения неэффективных и остальных работников по шкале Sp
Зеленая линия показывает распределение показателей шкалы Do неэффективных, красным - остальных. Серая область - неопределенность прогноза.
Т.е. если кандидат покажет при приеме на работу результат 45 баллов по шкале Sp, это не гарантирует нам, что он обязательно будет неэффективным. Сохраняется вероятность, что он может быть нормальным работником. Те, кто показывают результаты между 50 и 55 баллами, находятся в еще бОльшей зоне неопределенности.
Диаграмма распределения неэффективных и остальных работников по шкале Do
Зеленая линия показывает распределение показателей шкалы Do неэффективных, красным - остальных. Серая область - неопределенность прогноза. Здесь ситуация еще хуже, чем в случае со шкалой Sp.
Как улучшить прогноз
В данной ситауции мы можем применить логистическую регрессию. Если кратко, то мы используем в прогнозе обе шкалы. Результат для специалистов
Call:
glm(formula = ef ~ Sp + Do, family = binomial, data = s)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.49596 -0.35637 -0.17792 -0.08149 2.33129
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 15.53472 4.57578 3.395 0.000686 ***
Sp -0.20930 0.05991 -3.494 0.000477 ***
Do -0.11659 0.05254 -2.219 0.026485 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 69.807 on 86 degrees of freedom
Residual deviance: 42.577 on 84 degrees of freedom
AIC: 48.577
Number of Fisher Scoring iterations: 6
Для неспециалистов такая таблица
Таблица точности прогноза. Модель 1
FALSE
|
TRUE
|
Итого
|
|
0
|
63
|
12
|
75
|
1
|
3
|
9
|
12
|
Итого
|
66
|
21
|
87
|
обозначения:
- 1 - неэффективные,
- 0 - остальные работники.
- TRUE - тех, кого по результатам теста мы отправили в неэффективные,
- FALSE - кого по результатам теста мы отправили в остальные.
Ячейки
- Ячейка "1-TRUE" показывает количество неэффективных работников, которых мы правильно предсказали (т.е. зачислили по результатам теста в неэффективные),
- ячейка 1-FALSE показывает количество неэффективных работников, которых мы НЕправильно предсказали (т.е. зачислили по результатам теста в эффективные).
- "0 FALSE" показывает, кого мы правильно определили как эффективных
- "0 TRUE" - кого мы неправильно определили как не эффективных (т.е. они на самом деле вполне справляются с работой, а мы их отправили в бан)
Получается, что из 21 работника, кого мы определили как неэффективных, реально неэффективных только 9...
Не очень веселая картина, верно? мы можем чуть подкорректировать прогноз, изменив границы принятия решения (специалисты меня поймут, не специалисты - просто принимайте к сведению)
Таблица точности прогноза. Модель 2
FALSE
|
TRUE
|
Итого
|
|
0
|
66
|
9
|
75
|
1
|
4
|
8
|
12
|
Итого
|
70
|
17
|
87
|
Таблица точности прогноза. Модель 3
FALSE
|
TRUE
|
Итого
| |
0
|
72
|
3
|
75
|
1
|
6
|
6
|
12
|
Итого
|
78
|
9
|
87
|
Предлагаю третью модель уже самим оценить
Выбор модели
определяется стратегией компании:
Первая модель подойдет компании, в которой широкий выбор кандидатов (мы каждого четвертого зачисляем в неэффектинвые) и нам нужна высокая точность в отклонении неэффективных кандидатов, жертвуя при этом, правда, эффективными. Т.е. стратегия такая: вычистим "виновных", заметая и "невиноватых тоже"
Третья модель - условно говоря, "презумция невиновности". Она хороша в ситуации, когда кандидатов не так много и нужно отсекать неэффективных наверняка
Аналитики для выбора модели прогноза точности пользуются Receiver Operator Characteristic (ROC) Curve
На этой диаграмме обозначены относительные (%) погрешности принятия решения.
На шкале Y деления означают следующую формулу:
- "1-TRUE" / ("1-TRUE" + "1-FALSE") - т.е. % правильно "вычисленных" неэффективных работников из обзщего числа неэффективных
- Ось X имеет следующую формулу делений
- "0 TRUE" / ("0 TRUE" + "0 FALSE") - т.е. % тех, кого мы неверно зачислили в неэффективные (т.е. они на самом деле справляются с работой)
По диаграмме заметно, что нет счастья в жизни:
Если мы максимизируем отсев неэффективных (т.е. отбросим ВСЕХ неэффективных), то можно заметить, что в этом случае мы в неэффективные будем зачислять примерно 30 % эффективных. И т.п..
Этот компромисс определяется неточностью модели, и мы всегды выбираем решение, которое нас максимально устраивает с т.з. нашей стратегии, ситуации на рынке и т.п..
Например, если мы выбираем жесткую стратегию отсева неэффективных, мы должны воспользоваться равенством
0, 06 > 1/(1+2,71828182845904523536^-(15.53472-0.20930*Sp-0.11659*Do))
Т.е. мы в это выражение подставляем полученный кандидатом результаты теста, и, если выражение корректно (т.е. правая часть меньше левой, меньше 0, 06), то принимаем кандидата на работу, а если равенство не выполняется, то отклоняем
Самое страшное
Ну а самое страшное - принятие решения или выбор пороговых значенийНапример, если мы выбираем жесткую стратегию отсева неэффективных, мы должны воспользоваться равенством
0, 06 > 1/(1+2,71828182845904523536^-(15.53472-0.20930*Sp-0.11659*Do))
Т.е. мы в это выражение подставляем полученный кандидатом результаты теста, и, если выражение корректно (т.е. правая часть меньше левой, меньше 0, 06), то принимаем кандидата на работу, а если равенство не выполняется, то отклоняем